IDENTITY MANAGEMENT IN
KNOWLEDGE GRAPHS
Joe Raad
ABIES Doctoral School
MIA-Paris, AgroParisTech, INRA - Paris, France
Supervisors: Juliette Dibie, Liliana Ibanescu
LRI, Paris Sud University, CNRS - Orsay, France
Supervisors: Nathalie Pernelle, Fatiha Saïs
Knowledge Graphs
Graph-based representation of some knowledge in a machine-readable format
[Linked Data Principles, Tim Berners-Lee, 2006]
4th principle: "Link your data to other people’s data to provide context."

LOD cloud diagram, by Richard Cyganiak and Anja Jentzsch. http://lod-cloud.net/
Linked Open Data (LOD) Cloud: a large decentralized Knowledge Graph
Why linking your data?
db:drug33 rdfs:label "Dolasetronum" .
db:drug33 db:associatedCondition db:nausea .
freebase:m.02jq1 freebase:objectName "Dolasetron" .
freebase:m.452as freebase:sell freebase:m.02jq1 .
freebase:m.452as freebase:location geonames:Paris .
db:drug33 owl:sameAs freebase:m.02jq1 .
Where to find a medicine for Nausea in Paris?
(data analysis, data integration → search engines, virtual assistants, recommender systems)
owl:sameAs
The Standard Semantic Web Identity Predicate
〈x,owl:sameAs,y〉
Same real-world entity with two names (IRIs): x and y
- Reflexive: ∀x →〈x,sameAs,x〉
- Symmetric:〈x,sameAs,y〉→〈y,sameAs,x〉
- Transitive:〈x,sameAs,y〉∧〈y,sameAs,z〉→〈x,sameAs,z〉
-〈x,sameAs,y〉∧〈x,p,z〉→〈y,p,z〉
Identity is Complex...
From a Philosophical Point of View
Since a ship may be considered the same ship, even though some (or even all) of its original components have been replaced by new ones

Identity is Complex...
From a Philosophical Point of View
Allowing two medicines with the same chemical structure to be considered the same in a scientific context, but different in a commercial context
(e.g., because they are produced by different companies)

Identity is Complex...
From an Operational Point of View (1/3)
Backlinks in the Web of Data cannot be followed
Necessity for an Identity Management Service
- Access Identity Links
- Access Identity Sets (after transitive closure)
Identity is Complex...
From an Operational Point of View (2/3)
(e.g. precision between 67% and 86% [OAEI 2017, OAEI 2018]
Necessity for an Efficient Identity Invalidation Approach
- Minimal Assumptions on the Data
- Scalable to the Web of Data
Identity is Complex...
From an Operational Point of View (3/3)
From a set of 250 owl:sameAs links, one Semantic Web expert judged that only 73 are correct identity links, whilst two other experts have judged 132 and 181 as true identity links, respectively
[Halpin et al., 2010]
rdfs:seeAlso, skos:exactMatch, etc. → subjective + limited inference
Necessity for a new Identity Relation
- Weaker notion of identity
- Explicitly represent the context in which two entities are identical
"The SameAs Problem"
The Web of Data contains a large* number of erroneous identity statements
This Thesis
How to limit the misuse of identity links in knowledge graphs?
CONTRIBUTIONS / OUTLINE
(different but complementary solutions)Ⅰ. Identity Management Service
Ⅱ. Identity Invalidation Approach
Ⅲ. Contextual Identity Relation
Ⅰ. Identity Management Service
"sameAs.cc: The Closure of 500M owl:sameAs Statements".
Extended Semantic Web Conference ESWC, 2018 (best resource paper award)
Related Work • Objectives • Approach • Use Cases
Related Work
(e.g. include skos:exactMatch, umbel:isLike)
Objectives
• explicitly claimed to be identical
• implicitly claimed to be identical (after transitive closure)
• only include owl:sameAs statements
(e.g. can be used by a DL reasoner to infer new facts)
Overall Idea / Contributions
- Largest dataset of owl:sameAs links extracted from the Web to date
- Approach for efficiently computing and storing the transitive closure
- - Minimum memory usage
- - HDT for compressing the explicit identity network (owl:sameAs links)
- - RocksDB for storing identity sets (no materialization of the closure)
- Efficient access to the identity links and their identity sets
- - Linked Data Fragments for querying triple patterns
- - HDT and CSV data dumps
- - APIs
- - Search bar
sameAs.cc

sameAs.cc

sameAs.cc

sameAs.cc

Analysis - Namespace Level

2.6K namespaces connected by 10.7K edges forming 142 components
Analysis - IRI Level
The largest identity set contains 177,794 IRIs that 'should' represent different names to the same real-world entity
http://dbpedia.org/resource/Albert_Einstein
http://dbpedia.org/resource/Basketball
http://dbpedia.org/resource/Coca-Cola
http://dbpedia.org/resource/Deauville
http://dbpedia.org/resource/Italy
http://dbpedia.org/resource/Lists_of_christian_religions
...
Ⅱ. Detecting Erroneous Identity Links
"Détection de liens d’identité erronés en utilisant la détection de communautés dans les graphes d'identité".
Revue des Sciences et Technologies de l'Information ISI, 2018
"Detecting Erroneous Identity Links on the Web using Network Metrics".
International Semantic Web Conference ISWC, 2018
Related Work • Objectives • Approach • Experiments/Evaluation
Related Work
[Acosta et al. 2013; Paulheim 2014; Papaleo et al. 2014; Cuzzola et al. 2015]
[Cudre-Mauroux et al. 2009; de Melo 2013; Valdestilhas et al. 2017; Hogan et al. 2012; Papaleo et al. 2014]
No approach has proven its feasibility on the Web of Data
No approach has proven its feasibility on the Web of Data
Objectives
Scalable to the Web of Data
No assumptions on the data
(e.g. UNA, textual description, schema mappings)
High accuracy, precision and recall
Provide materialized and public results on real-world data
Overall Idea

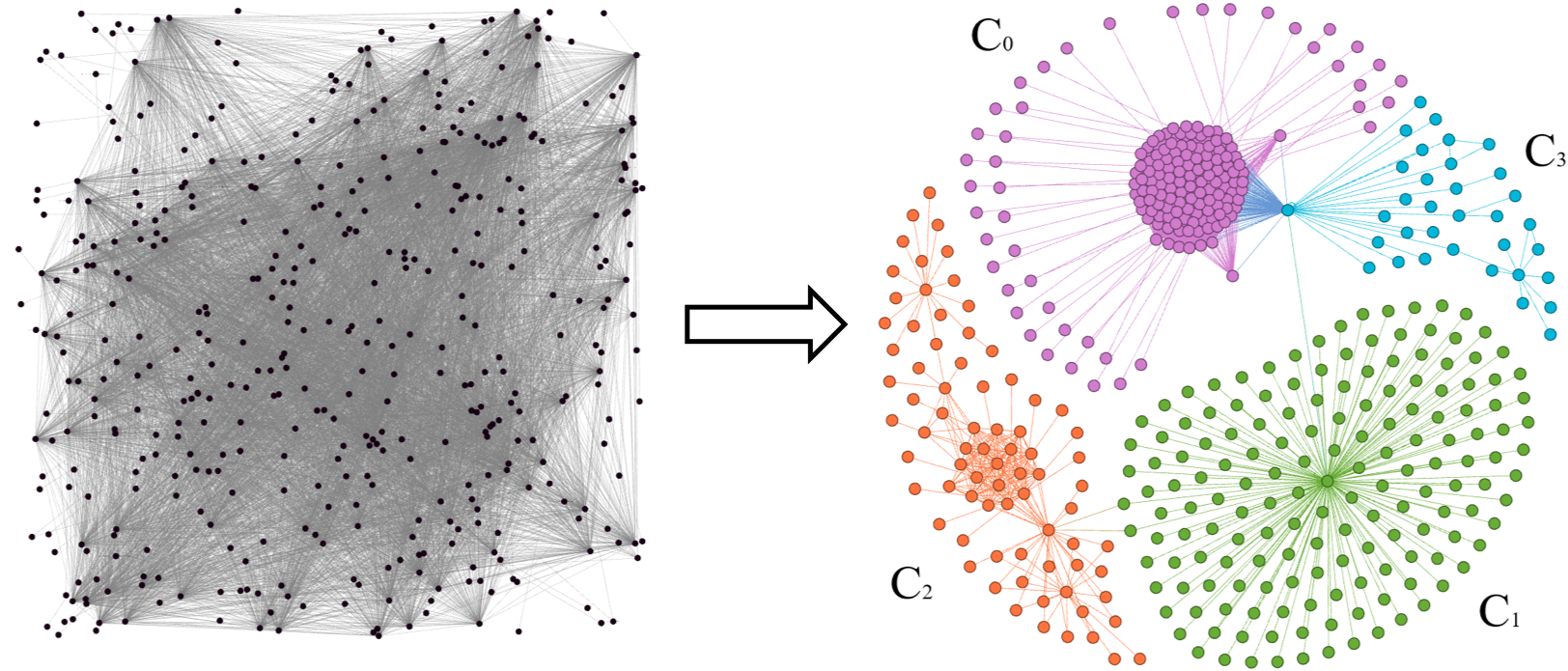
Identity Link Invalidation Approach[4 main steps]
(weighted network of owl:sameAs links)
2. Partition the sameAs network into equality sets
(connected component theoretically representing the same entity)
- Adapted to weighted networks
- Low computational complexity [O(n log n)]
- Outperforms other algorithms [Lancichinetti and Fortunato. 2009; Yang et al. 2016]
Identity Link Invalidation Approach[4 main steps]
1. Extract the explicit identity network
(weighted network of owl:sameAs links)
2. Partition the sameAs network into equality sets
(connected component theoretically representing the same entity)
3. Detect the community structure within each equality set


Quantitative Evaluation

(total runtime: 11 hours on 2 CPU cores)
- Check if links with high error degree have higher probability of incorrectness
- Fix a threshold that maximizes accuracy, precision and recall
Qualitative Evaluation (1/2)
Manual evaluation of 200 random owl:sameAs by 4 Semantic Web experts
| 0-0.2 | 0.2-0.4 | 0.4-0.6 | 0.6-0.8 | 0.8-1 | Total | |
|---|---|---|---|---|---|---|
| Total | 40 | 40 | 40 | 40 | 40 | 200 |
| can't tell | 5 | 18 | 19 | 31 | 18 | 91 |
| same | 35 (100%) |
22 (100%) |
18 (85.7%) |
7 (77.8%) |
15 (68.2%) |
97 (89%) |
| related + unrelated | 0 (0%) |
0 (0%) |
3 (14.3%) |
2 (22.2%) |
7 (31.8%) |
12 (11%) |
1. The higher an error degree is, the more likely an owl:sameAs link is erroneous
2. All evaluated links with an error degree ≤ 0.4 are correct
Qualitative Evaluation (2/2)
- 258 owl:sameAs extracted from the dataset (78 from gold standard)
- 780 injected erroneous owl:sameAs (from 40 random different terms)
- 71% precision (TP / TP + FP)
- 91% recall (TP / TP + FN)
- 92% accuracy (TP + TN / Total)
- 1.2M owl:sameAs with an error degree > 0.99
Additional Evaluation
precision increases from 40% in random equality sets to 88% in the largest equality set
discarded the weight from the error degree → precision drops from 88% to 11% in the largest equality set
We estimate that 4% of owl:sameAs links in the LOD Cloud are erroneous
(around 22 million owl:sameAs)
(based on error degree distribution + number of symmetrical links)
Identity depends on who's asking
Some of the detected owl:sameAs are clearly erroneous〈Bolivia, owl:sameAs, Albert_Einstein〉
Some identity assertions relate two closely related terms that are considered the same in some applications but not in others
(explains the disagreement between Semantic Web experts in judging owl:sameAs links [Halpin et al. 2010])
We need a contextual identity relation
Ⅲ. Contextual Identity Relation
"Comment représenter et découvrir des liens d’identités contextuels dans une base de connaissances : applications à des données expérimentales en science du vivant".
Revue d’Intelligence Artificielle RIA, 2018
"Detection of Contextual Identity Links in a Knowledge Base".
Knowledge Capture Conference K-Cap, 2017
"Détection de liens d’identité contextuels dans une base de connaissances".
28es Journées francophones d’Ingénierie des Connaissances IC, 2017 (best paper award)
"PO2 - A Process and Observation Ontology in Food Science. Application to Dairy Gels".
Research Conference on Metadata and Semantics Research MTSR, 2016
Related Work • Objectives • Approach • Experiments
Related Work
• Alternative Predicates (skos:exactMatch, Similarity Ontology)
[Halpin et al., 2010]
[Beek et al., 2016]
Contextual Identity Objectives
1. Explicitly associate the identity relation to a context
Contextual Identity - Example

In which context “drug1” is considered as identical to “drug2”?
Contextual Identity - Example

1. In a context where we discard the property “name” and “hasValue”
Contextual Identity - Example

2. In a context where we discard the property “name” and the Weight of Lactose
Contributions / Approach
1. Introduce the notion of a Global Context
(a global context is a sub-ontology represented as a Named Graph in RDF)
Given an RDFS Ontology O = (C, P, A) with
C = set of classes
P = set of properties
A = set of axioms (e.g. domains and ranges, subsumption)
A (Global) Context is a sub ontology GCu = (Cu, Pu, Au) with
Cu ⊆ DepC ⊆ C
Pu ⊆ P
Au = domain and range axioms more specific than those described in A
Some contexts are more specific than others (order relation)
GCu ≤ GCv
if Cv ⊆ Cu, Pv ⊆ Pu, and ∀p ∈ Pv:
domainv(p) ⊑ domainu(p) and rangev(p) ⊑ rangeu(p)
Contributions / Approach
1. Introduce the notion of a Global Context
(a global context is a sub-ontology represented as a Named Graph in RDF)
(if their contextual descriptions are isomorphic up to a renaming of the instances IRI)

Contributions / Approach
1. Introduce the notion of a Global Context
(a global context is a sub-ontology represented as a Named Graph in RDF)
2. Define the conditions in which two class instances are identical in a Global Context
(if their contextual descriptions are isomorphic up to a renaming of the instances IRI)
3. Detect the most specific Global Context(s) in which a pair of instances of a target class are identical

Contextual Identity in Practice
Can these identity links be detected in a real-world knowledge graph?
What is the benefit of having contextual identity links in a knowledge graph?
Complex case:
Scientific data in the domain of Life Sciences
Complexity - Life Sciences Data
Conditions tend to change even slightly from one experiment to another
→ things can rarely be declared the same
(e.g. not the exact same materials, different sample size, different experts)
Identity depends on each expert and application
→ impossible that experts manually provide all possible contexts
Complex Ontologies
(large number of classes, different granularity, long paths for attaining literal values)
Current Situation: disconnected experiments or erroneous owl:sameAs
→ limited or erroneous inferences
In addition to identity problems...
1. Syntactic Problems
heterogeneity of the formats in which scientific data are published
2. Semantic Problems
terminological variations encountered across the multiple scientific datasets
(e.g. synonyms, aliases, multilingualism)
LIONES Project
[FAIR principles, 2016]
Best practices: adopt Linked Data principles
(construct 5-star knowledge graphs)
[Linked Data Principles - Tim Berners-Lee, 2010]
Process and Observation Ontology (PO2)

5-star Knowledge Graph for Life Sciences

Contextual Identity for Life Sciences

| Mixture | Step | |
|---|---|---|
| # Individuals of target class | 1,187 | 581 |
| # Possible pairs | 703,891 | 168,490 |
| # Different Global Contexts | 2,232 | 718 |
| # Identity Links | 1,279,376 | 348,017 |
| # Most Specific Global Context per pair | 1.81 | 2.06 |
Contextual Identity for Rule Detection
identical〈GCi〉(x, y) ∧ observationMeasure(x, m1) → observationMeasure(y, m2) with m1 ≃ m2after exploiting the global contexts order relation
Example: identical〈GC3〉(x, y) → same(pH)
[4.5% error rate; 647 support]
x and y have the same citric acid weight

Conclusion &
Perspectives
Research Question
How to limit the misuse of identity links
in Knowledge Graphs?
Results Summary
• Largest collection of semantically interpretable identity statements and its transitive closure
• Efficient solution to compute the closure and store/access the sameAs statements and closure
Help users/applications in finding and reusing identical terms → enhance identity-based systems (e.g. question answering under entailment, ontology alignment)
• Use community structure and link symmetry to assign an error degree for each owl:sameAs link
• No assumptions on the data, scales to the Web (increases SoA by an order of magnitude)
Detect erroneous identity links and validate correct ones (precision/recall depends on threshold)
• Explicitly associate the context(s) in which two instances are identical (context is a sub-ontology)
• Approach for automatically detecting contextual identity links (can use experts knowledge to filter irrelevant contexts, tested on a newly constructed knowledge graph for life sciences)
Exploited for detecting rules to predict missing information, store/query the similarity of instances
Perspectives
Combine different community detection techniques (e.g. choose technique resulting highest network modularity, combine error degrees, or choose a technique depending on the network structure)
Include equality set's size (study its impact on precision e.g. # terms, # links, or # communities)
Combine different invalidation approaches (apply other techniques on links with high error degree)
Relaxed identity of literals (study its impact on inference)
Adapt relation to ontology mappings
Relax algorithm constraints (e.g. use all ontology classes)
Calculate contexts of difference (contextual identity do not distinguish between the absence of a property and the difference of the property values)
Detect causal rules (e.g. combine contexts of identity/difference with the instances temporal aspects)
Thank You!
- J. Raad, W. Beek, N. Pernelle, F. Saïs, and F. van Harmelen
"Détection de liens d’identité erronés en utilisant la détection de communautés dans les graphes d'identité".
Revue des Sciences et Technologies de l'Information ISI, 2018 - J. Raad, N. Pernelle, F. Saïs, J. Dibie, L. Ibanescu, and S. Dervaux
"Comment représenter et découvrir des liens d’identités contextuels dans une base de connaissances :
applications à des données expérimentales en science du vivant".
Revue d’Intelligence Artificielle RIA, 2018 - J. Raad, W. Beek, F. van Harmelen, N. Pernelle, and F. Saïs
"Detecting Erroneous Identity Links on the Web using Network Metrics".
International Semantic Web Conference ISWC, 2018 - W. Beek, J. Raad, J. Wielemaker, and F. van Harmelen
"sameAs.cc: The Closure of 500M owl:sameAs Statements".
Extended Semantic Web Conference ESWC, 2018 (best resource paper award) - J. Raad, N. Pernelle, and F. Saïs
"Detection of Contextual Identity Links in a Knowledge Base".
Knowledge Capture Conference K-Cap, 2017 - J. Raad, N. Pernelle, and F. Saïs
"Détection de liens d’identité contextuels dans une base de connaissances".
28es Journées francophones d’Ingénierie des Connaissances IC, 2017 (best paper award) - L. Ibanescu, J. Dibie, S. Dervaux, E. Guichard, and J. Raad
"PO2 - A Process and Observation Ontology in Food Science. Application to Dairy Gels".
Research Conference on Metadata and Semantics Research MTSR, 2016
Annex
FINDING THE THRESHOLD (1/2)
Manual evaluation of 200 random owl:sameAs by 4 Semantic Web experts

1. All evaluated links with an error degree ≤ 0.4 are correct
2. The higher an error degree is, the more likely an owl:sameAs link is erroneous
FINDING THE THRESHOLD (2/2)
Manual evaluation of 60 owl:sameAs with err > 0.9

Accuracy / Recall Evaluation
(threshold 0.99)
[Acosta et al. 2013]
(error degree ranging from 0.52 to 0.94)
98.7% Accuracy
Randomly chose 40 different terms (e.g. dbr:Strawberry, dbr:Chair)
not explicitly sameAs but some in the same equality set
Added all the possible 780 links between them
725/780 have an error degree > 0.99
(error degree ranging from 0.87 to 0.9999)
93% Recall
Qualitative Evaluation
TN: correct sameAs + error degree ≤ 0.99
TP: erroneous sameAs + error degree > 0.99
| TN | TP | FN | FP | Total | |
|---|---|---|---|---|---|
| Sample 1 [200 random sameAs] | 97 | 0 | 12 | 0 | 109 |
| Sample 2 [60 sameAs > 0.9] | 6 | 20 | 5 | 8 | 39 |
| Sample 3 [Obama Equality Set] | 30 | 2 | 0 | 0 | 32 |
| Sample 4 [DBPedia-Freebase sameAs] | 77 | 0 | 0 | 1 | 78 |
| Sample 5 [Injected erroneous sameAs] | 0 | 725 | 55 | 0 | 780 |
| Total | 210 | 747 | 72 | 9 | 1038 |
Symmetry Impact (1/2)
| Symmetrical | Non-symmetrical | Total | |
|---|---|---|---|
| Total | 94 | 164 | 258 |
| same | 92 (98%) |
127 (77%) |
219 (85%) |
| related + unrelated | 2 (2%) |
37 (23%) |
39 (15%) |
1. Symmetrical owl:sameAs links are more likely to be correct
Symmetry Impact (2/2)
Discarded the weight from the error degree
Manual evaluation of 30 sameAs links with error degree > 0.99 + in the largest equality set
Only 2 erroneous owl:sameAs
(17 correct and 11 can't tell)
Precision drops from 88% to 11%
(in the largest equality set)
Equality Set - 'Barack Obama'
Who is messing up the LOD Cloud?
freebase:m.05b6w1g owl:sameAs dbr:President_Barack_Obama
freebase:m.05b6w1g owl:sameAs dbr:President_Obama
freebase:m.05b6w1g freebase:object.name "Presidency of Barack Obama"@en
(in the 'Barack Obama' equality set)
How messed up is the LOD Cloud?
Our approach can give an approximation based on:
1. nbr of symmetrical sameAs
(450M owl:sameAs with 98% chance of correctness)
2. nbr of non-symmetrical sameAs with err degree ≤0.99
(105M owl:sameAs with a 88.6% chance of correctness)
3. nbr of non-symmetrical sameAs with err degree >0.99
(1.2M owl:sameAs with an erroneous probability between 40 and 88%)
We estimate that 4% of owl:sameAs links in the LOD are erroneous
(around 22.5M links)
previous estimations:
2.8% by [Hogan et al. 2012] and 21% by [Halpin et al. 2010]
DECIDE (1/3)

DECIDE (2/3)

DECIDE (3/3)
